

Which companies will win the AI race? Those with Loop Control
Which companies will win the AI race? Those with Loop Control
In Part I we break out the economic and market dynamics of AI

Humans are about to give up their 200,000 year monopoly on thinking. As we transition from meat- to silicon-based cognition, new empires of wealth will be built. Who will be the Standard Oil and US Steel of this revolution?
To tackle this question we’ll dig into the basic economic and market dynamics of AI. The important conclusions, as I see them, are as follows:
Task-engaged AIs will dominate value creation. Current state-of-the-art AIs (LLMs) are oracles — they respond to requests with output streams of text or media but have no direct engagement with the task or the result of the task (other than a crude thumbs up or down). Task-engaged AIs, on the other hand, have direct connections to task context, actions, and results — and are part of the feedback loop. We should expect transformative economic impacts when task-engaged AIs mature, not before.
The AI value chain will become commoditized everywhere except proprietary data. In the near term, winners may emerge based on advantages in access to compute and R&D talent, as these remain severely supply constrained, but, long term, proprietary data is the only real differentiator. This means companies that own the end-usage feedback loop and thus generate the proprietary data necessary to improve the AI model — companies that have what I call loop control — will capture the most value.
Example: Tesla and Waymo own the end-usage feedback for their self-driving AIs; the OpenAI GPT-4 api does not.

Loop control
Feedback loops, and therefore AIs, are demarcated by their interface and environment — Loop control cannot naturally expand beyond a given interface in a given environment, because the AI is only trained against those. Conversely, and more interestingly, an AI with a given interface in a given environment will subsume all tasks amenable to that interface in that environment.
Example: The driving loop
Interface input: video, lidar, etc.
Interface output: steering wheel, pedal movements, etc.
Environment: physical, vehicular
Tasks: passenger vehicle driving, commercial truck driving, food delivery, package delivery — all possible driving tasks
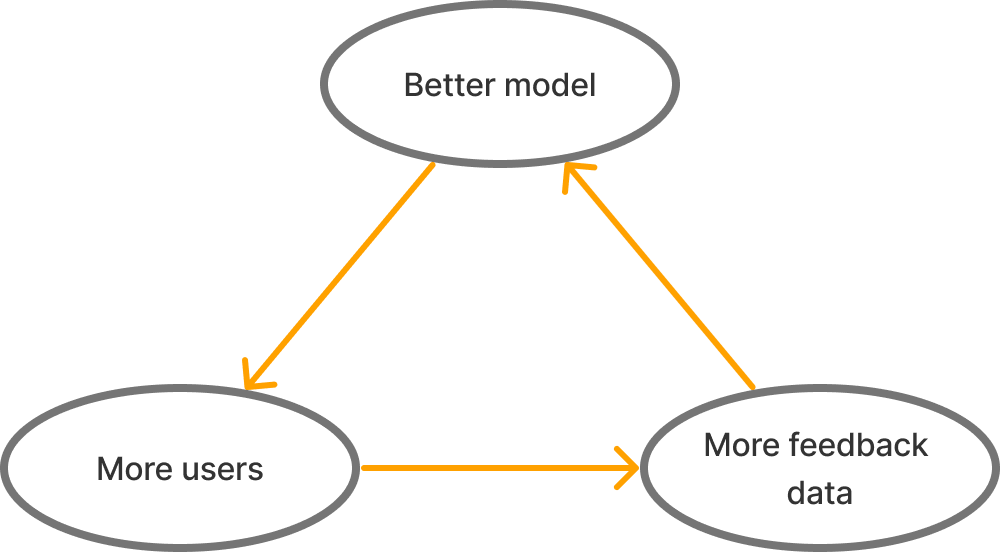
Because of the flywheel of loop control (more usage → more data → better AI → better product → more usage) each loop will end up dominated by a single loop dominant AI that develops a lead in usage and then accelerates away from its competitors, and owns all tasks in that interface-environment loop.
Example: Tesla will be the loop dominant AI for the “driving loop” described above — it has the most data and the most users and no other company will be able to catch up once the AI flywheel starts. (Tesla could misstep, of course.)
Loop dominant AIs will own huge portions of the economy in a way few companies ever have. Just as Google and Facebook, with their data feedback loops and super aggregator dynamics, were able to capture so much of the internet’s value, loop dominant AIs will do the same for these and other markets, but go far beyond, aggregating all demand for all tasks in their interface-environment and commoditizing their suppliers. Exactly how dominant they are in their domain will depend on the complexity and depth of knowledge required for relevant tasks (i.e. how much proprietary data is required), and how easily this knowledge can be commoditized (via simulation, for instance). I discuss knowledge commoditization in depth in this post.
Example: Tesla will capture a significant share of the total economic value of all driving activity, wherever their AI is legally allowed to drive. This is true if, and while, state-of-the-art driving knowledge remains un-commoditized.
The default loop (or digital loop) is the universal personal assistant loop. It can interact with humans via text, audio, and video to accomplish any digital task.
Example: The default loop
Input: text, audio, video, dynamic UIs
Output: text, audio, video, various digital actions (e.g. generic phone and web browsing)
Environment: social, digital
Tasks: chatting, doing your taxes, writing an email, sending a birthday present — any possible digitizable task.
The loop dominant AI for the default loop will be the most important AI, by far, called the default AI. Think Google, but capable of completing any task for you, not just answering any question. By the nature of aggregation, and the demands of the data flywheel, the default AI will necessarily be open-access, affordable, and commercial so as to aggregate the most data and usage and amortize reinvestment in the AI over the largest revenue base.
Open source AIs will excel in use cases with commoditized knowledge. The problem will be that loop dominant AIs will provide this commoditized knowledge for free as well, in additional to any proprietary knowledge, with the additional resources to provide a better user experience. The market dictates that loop dominant AIs will give away huge amounts of value for free to retain loop control and monopolize end-usage feedback, in much the same way that Google gives away billions of dollars worth of operating system, browser, and, well, dollars today to maintain access to user’s queries. Open source won’t have any chance of competing for users.
In a future post I will catalog the major loops and which companies are likely to dominate each of them. Here, we’ll continue to focus on the default loop (as the most important loop) and the driving loop (as a simpler, illustrative example).
AI as an economic good
AI as an actual commercial product manifests as a trained model generating output, i.e. making predictions or choosing actions. This output can be anything — text, audio, video, api calls, motor actuations, etc. Such an AI has low marginal cost, just the energy and GPU utilization to generate the output, high fixed investments of R&D, infrastructure, and model training, and, therefore, strong economies of scale: once you train a large AI model, and spin it up on a large GPU cluster, it is very little extra work to clone another such GPU cluster.
This means AI is likely to replicate a lot of the market dynamics of internet-age super aggregators like Google and Facebook, which face the same near-zero marginal costs, high fixed investments, and instant global distribution that imply a winner-take-all dynamic.
Although technically the GPUs and energy used to produce AI output are rival and it would be possible to make AI excludable, in practice, like search engines, AI will present as a public good thanks to the returns to scale inherent to AI. We’ll discuss this more below.
The AI supply chain
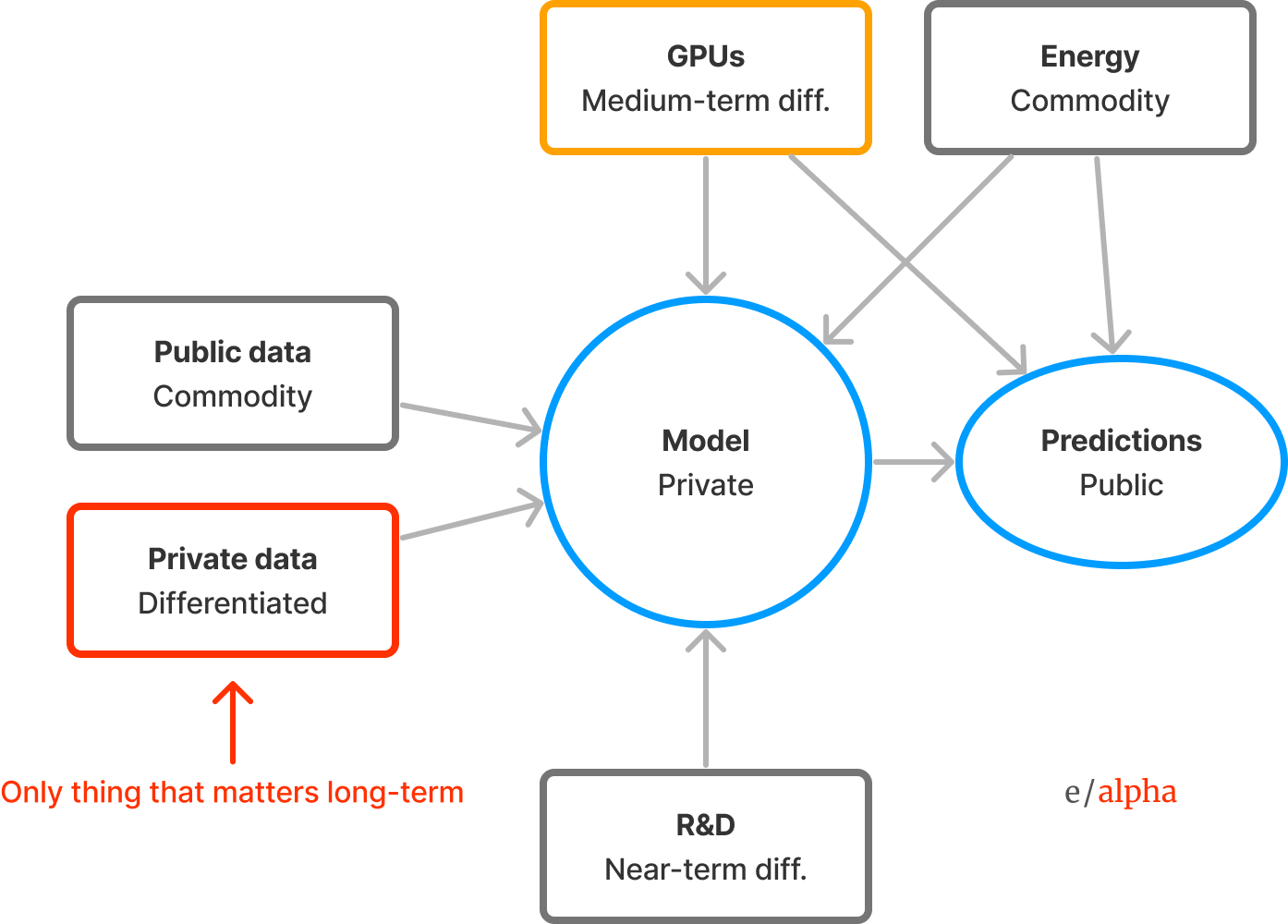
AI has four primary inputs:
Compute - GPU chips to run the model
Energy - to run the chips
Data - to train the neural network
R&D - to design, build, and manage the AI system
And one intermediate and one final output:
Neural network (model) - intermediary output
Predictions - the final output of the model
Compute
We can assume, in the medium run, that compute will become commoditized enough, as it has for previous computer revolutions. For now though, there are only a few players in the AI compute game, and there are significant barriers, with Nvidia as the only independent supplier with real volume. All of the big cloud players are looking to build vertically integrated AI chip offerings, but only Google has developed something competitive so far. All are supply constrained, and Nvidia has pre-bought a big portion of supplier capacity. All steps of the GPU supply chain are human- and physical-capital intensive, and scaling capacity will take time. But with the amount of money at stake, expect the market to find creative solutions, and eventually oversupply, as tends to happen in technology revolutions.
Energy
Energy is generally commoditized, but there can still be strong local effects — placing your training data center next to a hydro facility, for instance. Energy is not a constraint at the moment in the production of AI, but it will become one as AI grows and chips become relatively more commoditized. We should expect to see dedicated nuclear reactors and solar farms powering AI data centers in the future, for instance.
R&D
To build a cutting-edge AI will likely continue to require large capex of compute and R&D. GPT-4 cost $50-100m in compute to train, it seems economical for GPT-5 to cost upwards of $1B. Those costs are matched by the high cost of the specialized experts that research and develop the models and systems, ones that have never been built before. Part of why OpenAI has a lead in AI models is because they committed early and big to large-scale transformer training runs, but partly also because of what appears to be superior R&D, as other companies have attempted to outspend but have come up short in performance. Nonetheless, thanks in part to America’s (and California’s specifically) laissez faire employment regulation, these R&D advantages tend to dissipate rapidly as talent moves between companies.
Data
Data is the heart of any AI. Despite 75 years of AI research into clever methods, the reality is that it is the “unreasonable effectiveness” of data and the “bitter lesson” of exponential compute that have brought us to where we are today. In the end it is the size and quality of your data (and having enough compute to digest it all) that ultimately determines the quality of your AI, full stop. As compute becomes commoditized and oversupplied, data will be the only long-term differentiator.
Current state-of-the-art AI (LLMs) are trained on large corpuses of text, most of which are open, or semi-open access data sets — internet text, web forums, books, research papers. We’ll call all this public data. It is undifferentiated and freely accessible.
Long-term, the value of a given AI, if it is to have any non-commoditized value at all, will necessarily come from its access to proprietary data.
In conclusion, the AI value chain will be fully dominated long term by proprietary data. In the near term, winners may emerge based on advantages in access to compute and R&D talent, as these remain severely supply constrained.
AI in the market
If we accept the following assumptions:
AI is a general purpose technology — it is widely useful to a large share of economic activity
The cost of developing a leading AI is very large, both in compute and R&D (as discussed above)
End-usage feedback (proprietary data) is the dominant factor in determining an AI’s performance at various tasks
Task performance (on economically important tasks) does not have a low ceiling that is reached quickly by cheap or small AIs
Then this implies that AI will be:
Monopolistic - The AI with the largest user base will gather more end-usage feedback data which will give it the better model which will attract more users, in a reinforcing flywheel of data, usage, and money.
Commercial - Governments will be constrained to just their own citizens, limiting their user base, and disadvantaging themselves in the competition for better feedback data. Open source models will not be able to support the speed of development and focus on best-in-world user experience required to stay first, nor will they have the resources to entice and retain users. This means AI will be developed by private companies with maximum (global) reach.
Open-access - Again, because of the need to maximize user data and amortize investments over the greatest amount of revenue, AI will be made available to everyone legally allowed.
Affordable - Once again, to maximize users, AI will provide its services mostly free of charge, with revenue generation tied to task completions (referral fee from the sub-service that executes the underlying task or advertising), and subscriptions for premium features or services.
Because of these properties, AI will be a great equalizing force for the world. Differences in intellectual capital, which today explain a lot of inter- and intra-country inequality in outcomes, will be leveled, globally. A 500 year old trend of increasing returns to intellectual capital in humans will be nullified, almost overnight.
Ways that open source could win
Although we’ve outlined why proprietary models are likely to dominate the market, there are a few scenarios where open-source models could end up winning.
AI plateaus quickly. This is maybe what we are seeing with helpful oracles — open-source models that can run on your laptop competing with proprietary models with 20 times the parameters, all of them producing pretty great output. In a couple of years, will there really be much room to grow? The issue here is that helpful oracles are just not that valuable relative to the task-competent AIs that are coming soon, and those can’t just be trained on open data. There is no foreseeable limit to the scope and skill that task-competent AIs will need to tackle, so a plateau seems unlikely.
Model scraping is very effective. Many of the best open source models and fine-tunes today are trained off of examples generated with GPT-4, what you could call “model scraping”. If you can sample enough of the problem space that you care about with a commercial model, and use its output to train your own problem-specific model, then it will be hard for the commercial model to defend against this, since it is bound by the open-access market requirement discussed above. You could see companies getting aggressive with detecting and punishing this behavior, but like with scrapers on the modern internet it is a cat and mouse game. Nonetheless legal issues would likely restrict the relevance of any such scraped model. More damning for this approach is that the sample space for important problems may just be too large for this to be practical. Unless…
Users or governments force data sharing. Users could demand that their end-usage feedback data be owned by them and that they can resell or share it. Or anti-trust law could expand to include restrictions on loop control. (We will discuss policies like this much more in the future, they will be incredibly important to get right.) The default is for users to just take the subsidized offerings provided by loop dominant companies since it is win-win for them and the company. This is exactly how the internet played out with Google and Facebook, we shouldn’t expect anything different here unless we get ahead of it with consumer awareness and regulation. But how do you regulate against consumer choice in a free country?
Synthetic / simulated data is sufficient. It’s possible in certain domains that simulated or synthetic end-usage data is sufficient for training state-of-the-art task-competent AIs. We’ve seen some of this already with model scraping. You could imagine, for instance, open-source driving AIs trained on simulated environments. Although no one will have access to the huge volume of real-world data that Tesla has, developing a simulated driving environment (as self-driving companies already have) and training your AI in that environment would be much cheaper and simpler. But this means your AI is only as good as your simulation, and how can you be sure your simulation is high fidelity in the rare circumstances that matter? Only by doing a lot of real world driving! So you are back to your original problem.
In short, none of these seem especially promising outside of perhaps regulation, and the issue with regulation is that it is jurisdiction by jurisdiction and competition makes coordination difficult.
If open-source doesn’t win, then which companies will?
This is an investor newsletter, after all. We’ve determined the winners will be the companies with the best user-data flywheel that can establish loop control. There are two starting points from which to jumpstart your flywheel:
Jumpstart with users - If you already have a lead in distribution to end-users, and you’re able to develop a good-enough AI, that should be sufficient to expand your distribution lead and get a nice flywheel going. In this category for the default loop: Google and Apple.
Jumpstart with AI - If your early AI is so much better than the established players that users start to migrate en masse, then you can further your AI lead and accelerate user switching, kicking off the flywheel. In this category for the default loop: OpenAI.
Which one will dominate?
It’s generally safe to assume distribution is much harder than product in most markets, so this seems like the obvious winner. And yet, generation after generation, technology disruption after disruption, incumbents fail to capitalize on their distributional advantage and succumb to tiny startups with better products that eat their way up-market. It’s a tale as old as tech.
It really comes down to the specifics of the technology disruption — its first use cases and customers and their relation to existing markets, how established companies can leverage the technology in existing offerings, if the technology cannibalizes existing business, etc. — these determine whether it’s a sustaining or disruptive technology.
In the case of AI, there are strong arguments in favor of incumbents with distribution winning out.
Why incumbents with distribution will obviously win
First, AI is a very capital intensive business. State-of-the-art models will cost billions of dollars to create. Startups can only hope to partner with, or piggyback off of, larger companies, as OpenAI has done with Microsoft.
Second, AI is data hungry, and incumbents have lots of proprietary data (with the right ToS) that could help them build better AIs out of the gate. Imagine Google training on all of Gmail, for instance, to build the best cold outbound email AI.
Third, in the few months of experience we have so far, there seems to be rapid convergence in AI tech across companies and open-source. Until there are proprietary data moats, there’s not much separating OpenAI from Anthropic from Gemini from Mistral. And that data moat will come from having distribution, not tech, ultimately.
And yet…
Why startups with great tech will obviously win
At the moment it’s the small startup OpenAI that has opened up a huge lead on its competitors in terms of tech, brand, and adoption. It’s done so by betting bigger and sooner on large transformer training runs, by having some of the top talent in the world, and by, well, not actually being entirely a small startup, but actually half incumbent through its partnership with the largest company in the world, Microsoft, giving it access to sufficient capital and compute.
And, exactly to script, Google, the natural incumbent, with every advantage possible and an initial head start (they invented the technology after all), has failed in the way incumbents always fail: being too risk-adverse, not experimenting in the market, ignoring opportunities that don’t help its current business, not incentivizing individual talent to build great products, etc.
The question is: can OpenAI maintain and extend this lead? Google has received the wake up call, as has the rest of big tech, with Google’s latest model roughly matching OpenAI’s, but a year late. OpenAI could leapfrog everyone again with GPT-5; will they be able to capture enough end users to start their own proprietary data flywheel? They’ve started in a small way with thumbs up/down in ChatGPT. But the flywheel only really starts when they start attempting to accomplish tasks, not just answer questions — which they appear to be working on.
This is likely a $10 trillion dollar question — the market for the default AI will be the biggest product market of all time. Who will win it? Will it be Google fulfilling its destiny? Or the plucky upstart OpenAI with its not so upstart-y partner Microsoft? Or will it be the dark horse, Apple, with its world-best integrated hardware and software systems, its massive distribution, its most respected brand, and its great consumer trust with data and privacy? Or will it be a company that we haven’t even heard of yet that reimagines what a company means in the age of AI — an AI-native corporation?
In Part II of this post I’ll explore which tasks will be the first AIs will tackle, and which initial interface-environments will have the most economic value, and how hardware platforms will factor in, and ultimately, how this determines who will win markets. Stay tuned.